Music Album Review Sentiment Analysis
A machine learning system that classifies music album reviews into 6 sentiment categories using Bi-Directional LSTM, Gated Recurrent Unit and traditional ML models.
Project Overview
This sentiment analysis system processes music album reviews and classifies them into 6 sentiment categories (0-5 stars) using advanced natural language processing techniques.
The project involved extensive data preprocessing, exploratory analysis, and implementation of both traditional machine learning models (Logistic Regression, SVM, Random Forest) and deep learning approaches (Bi-Directional LSTM). The system handles class imbalance through oversampling and achieves strong performance metrics.
We use BiDirectional LSTM over GRU even its accuracy is better than Bidirectional LSTM because Bidirectioanl LSTM can better perform on ambiguous sentences due to its dual traversal.
Technical Highlights
Data Processing
- 78,162 music album reviews
- Handled class imbalance with oversampling
- Text cleaning and tokenization
Model Architecture
- Bi-Directional LSTM with embedding layer
- Global max pooling
- Dense layers with dropout
Evaluation
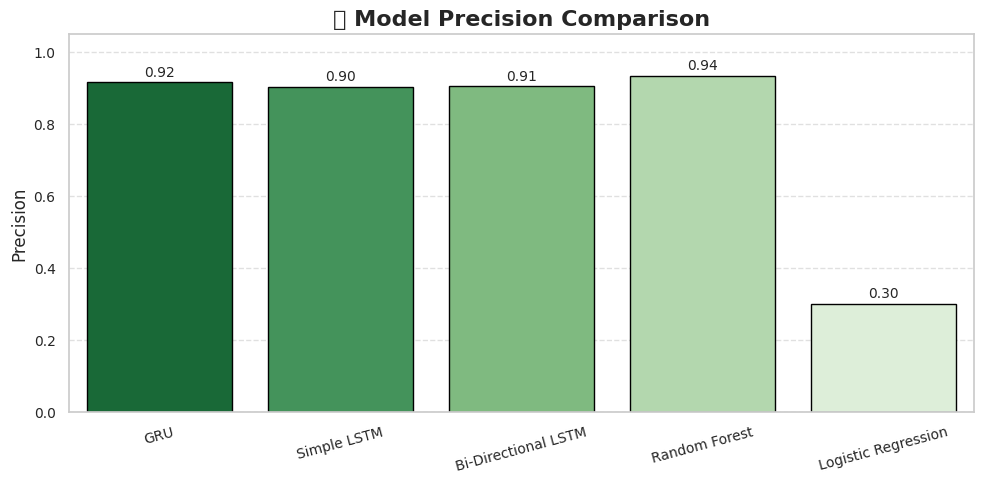
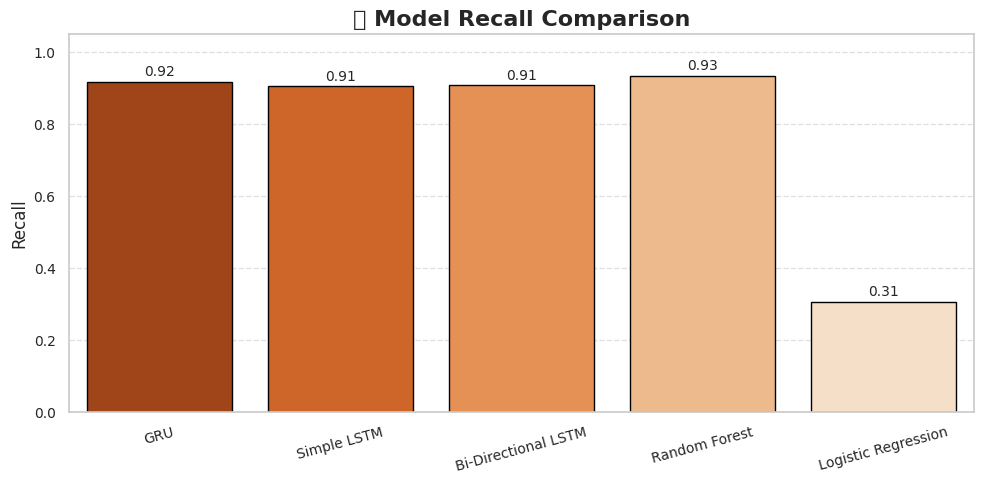
- Accuracy, Precision, Recall metrics
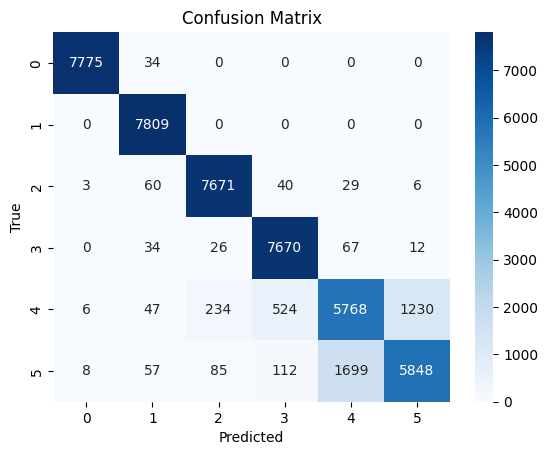
- Confusion matrix analysis
- Comparison with traditional ML models
Technologies
- TensorFlow/Keras for deep learning
- Scikit-learn for traditional ML
- Pandas/Numpy for data manipulation
Model Performance
Accuracy
86.4%
Bi-Directional LSTMPrecision
85.2%
Weighted averageRecall
86.4%
Weighted averageModel Comparison
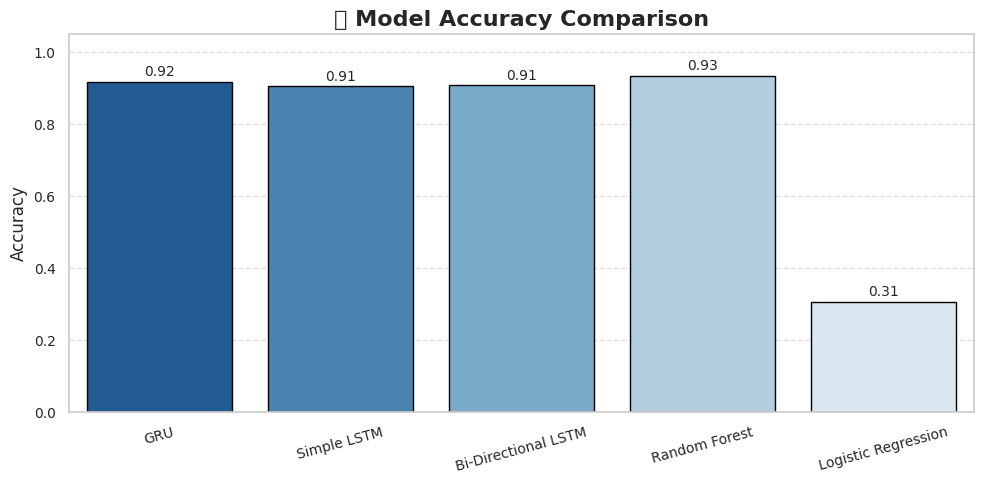
The Bi-Directional LSTM outperformed traditional machine learning models:
- Logistic Regression: 78.3% accuracy
- Random Forest: 81.6% accuracy
- SVM: 79.8% accuracy
Project Links
View Source Code View Visualizations Download Report📊 Project Details
- Status: Completed
- Dataset: 78,162 reviews
- Classes: 6 sentiment levels
- Framework: TensorFlow 2.x
Technology Stack
Core Libraries
TensorFlow Keras Scikit-learn Pandas NumpyNLP
NLTK Tokenizer Word EmbeddingsVisualization
Matplotlib Seaborn PlotlyDataset Information
Original Distribution
- 5-star: 29,520 (37.8%)
- 4-star: 39,045 (49.9%)
- 3-star: 4,430 (5.7%)
- 2-star: 4,245 (5.4%)
- 1-star: 525 (0.7%)
- 0.5-star: 397 (0.5%)
After Oversampling
Balanced to 39,045 samples per class
Data Visualizations
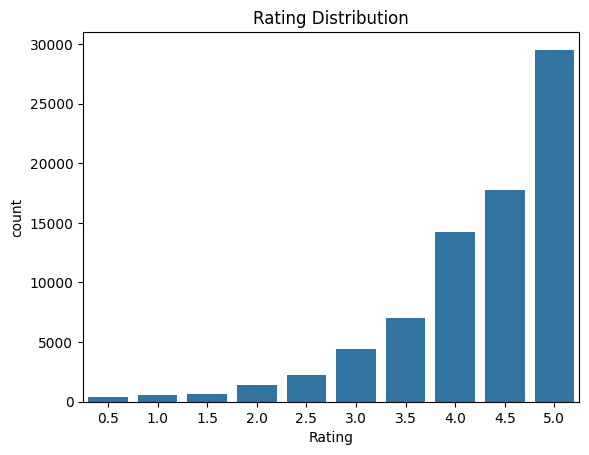
Original rating distribution showed extreme imbalance with most reviews being 4 or 5 stars. Oversampling was applied to create balanced classes for training.
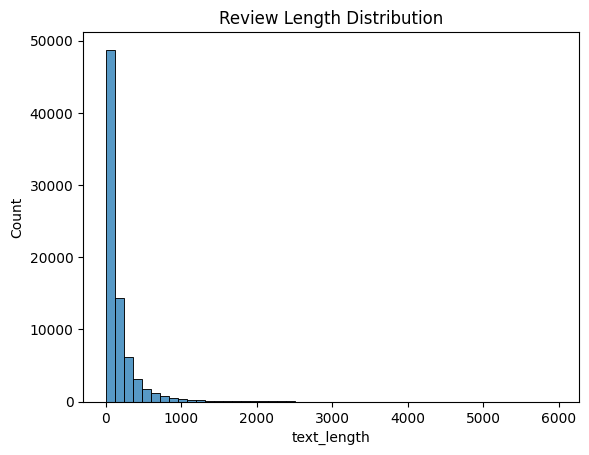
Review length analysis showed most reviews under 600 words. The 95th percentile was used to determine optimal padding length for the LSTM model.

The Bi-Directional LSTM architecture with embedding layer, global max pooling, and dense layers with dropout achieved the best performance.
Technical Challenges & Solutions
The original dataset had extreme class imbalance with 49.9% 4-star and 37.8% 5-star reviews, while other classes were underrepresented.
Solution: Implemented oversampling to balance all classes to 39,045 samples each, ensuring the model wouldn't be biased toward majority classes.
Review lengths varied from a few words to thousands, making consistent model input challenging.
Solution: Analyzed length distribution and used the 95th percentile (612 words) as max length for padding/truncation.
Needed to determine whether traditional ML or deep learning would perform better for this task.
Solution: Implemented and compared Logistic Regression, SVM, Random Forest, and Bi-Directional LSTM models.
Key Code Implementation
Bi-Directional LSTM Model Architecture
model = tf.keras.Sequential([
tf.keras.layers.Embedding(input_dim=30000,
output_dim=128,
input_length=max_len),
tf.keras.layers.Bidirectional(
tf.keras.layers.LSTM(64, return_sequences=True)),
tf.keras.layers.GlobalMaxPooling1D(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(6, activation='softmax')
])Data Preprocessing
# Handle class imbalance through oversampling
dfs = [df[df['Rating_Class'] == i] for i in range(6)]
max_count = max(len(d) for d in dfs)
dfs_balanced = [resample(d, replace=True,
n_samples=max_count,
random_state=42)
for d in dfs]
df_balanced = pd.concat(dfs_balanced)Text Tokenization
tokenizer = Tokenizer(num_words=30000, oov_token='')
tokenizer.fit_on_texts(df_balanced['Review'])
sequences = tokenizer.texts_to_sequences(df_balanced['Review'])
padded = pad_sequences(sequences, maxlen=max_len,
padding='post', truncating='post')