Movie Recommendation System
A content-based recommendation engine that suggests similar movies based on cosine similarity of movie features.
Project Overview
This project implements a content-based movie recommendation system that suggests similar movies based on their features like genres, keywords, cast, crew, and overview.
The system analyzes the TMDB 5000 movies dataset, processes the textual features using NLP techniques, and computes cosine similarity between movies to find the most similar ones. It demonstrates how machine learning can power personalized recommendations.
System Architecture
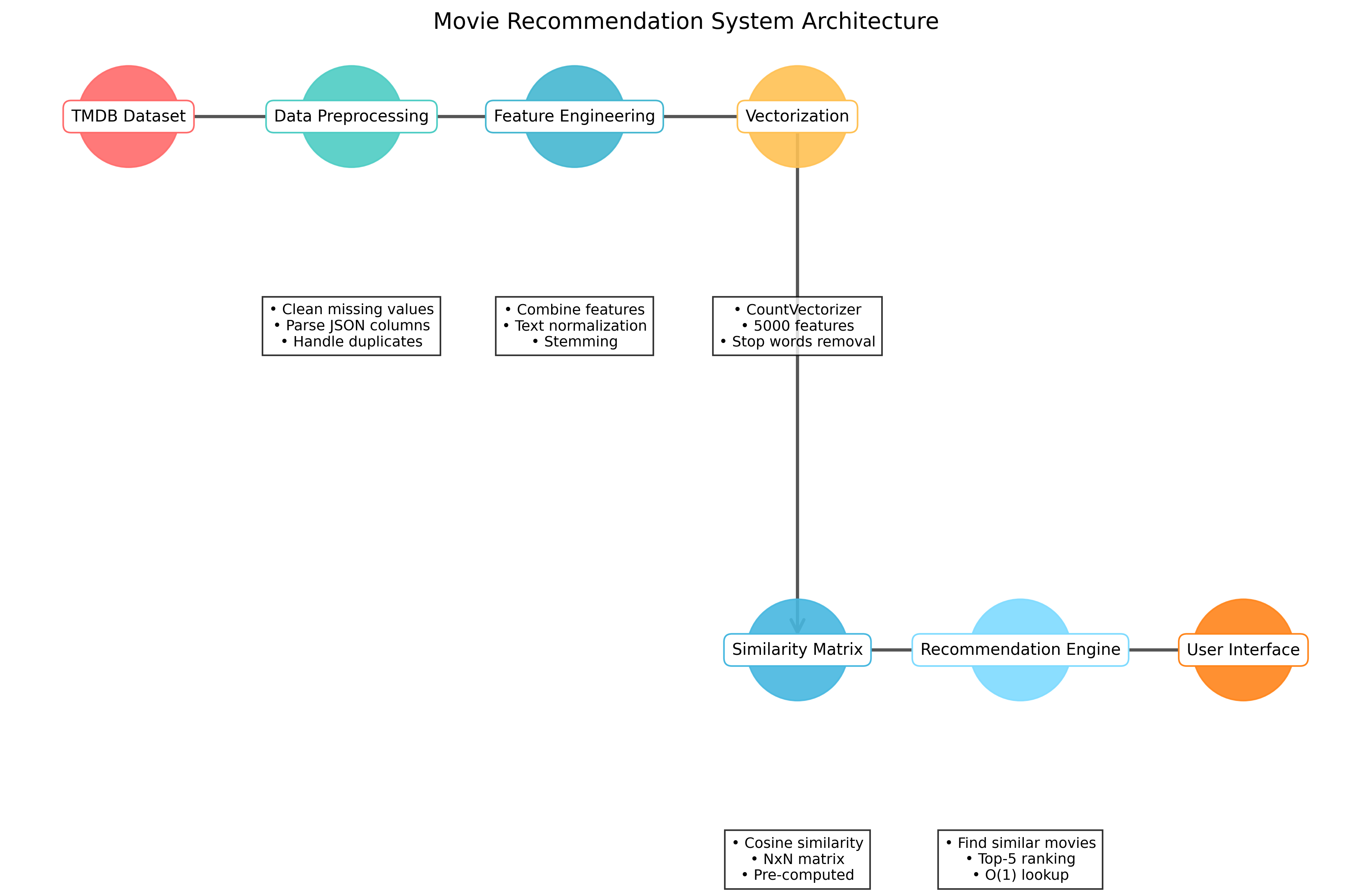
Technical Highlights
Data Processing
- Merged TMDB movies and credits datasets
- Extracted relevant features (genres, keywords, etc.)
- Handled missing values
- Processed JSON-like columns
Text Processing
- Converted JSON to lists of features
- Combined multiple features into tags
- Applied stemming with Porter Stemmer
- Lowercased and removed spaces
Vectorization
- CountVectorizer with 5000 features
- English stop words removal
- Bag-of-words representation
- Sparse matrix conversion
Recommendation
- Cosine similarity calculation
- Top 5 similar movies
- Content-based filtering
- Fast lookup with movie indices
System Results
Movies Processed
5,000+
From TMDB datasetFeatures Combined
5
Genres, keywords, etc.Processing Time
<1 min
On standard hardwareRecommendation Quality
The system provides:
- Genre-based similarity: Movies with similar genres
- Content-based similarity: Movies with similar plots
- Cast/crew similarity: Movies with same actors/directors
- Keyword matching: Movies with similar themes
Recommendation Examples
Input Movie: The Dark Knight
Recommended Movies:
- The Dark Knight Rises
- Batman Begins
- Batman v Superman: Dawn of Justice
- Man of Steel
- Watchmen
Input Movie: Inception
Recommended Movies:
- The Matrix
- Shutter Island
- Interstellar
- The Prestige
- Source Code
Input Movie: Toy Story
Recommended Movies:
- Toy Story 2
- Toy Story 3
- Monsters, Inc.
- Finding Nemo
- Up
Project Links
View Google Colab Notebook View Visualizations Download Jupyter File📊 Project Details
- Status: Completed
- Dataset: TMDB 5000 Movies
- Features: Genres, Keywords Cast, Crew, Overview
- Algorithm: Cosine Similarity
Technology Stack
Core Libraries
Pandas NumPy Scikit-learn NLTKData Processing
JSON Parsing Text Cleaning Feature CombinationNLP
CountVectorizer Porter Stemmer Stop WordsDataset Information
TMDB 5000 Dataset
- 5000+ movies with detailed metadata
- Genres, keywords, cast, crew information
- Movie overviews/plot summaries
- Ratings and popularity metrics
Features Used
Genres, keywords, overview, cast (top 3), director
System Visualizations
The data processing pipeline shows how raw movie data is transformed into feature vectors for recommendation.
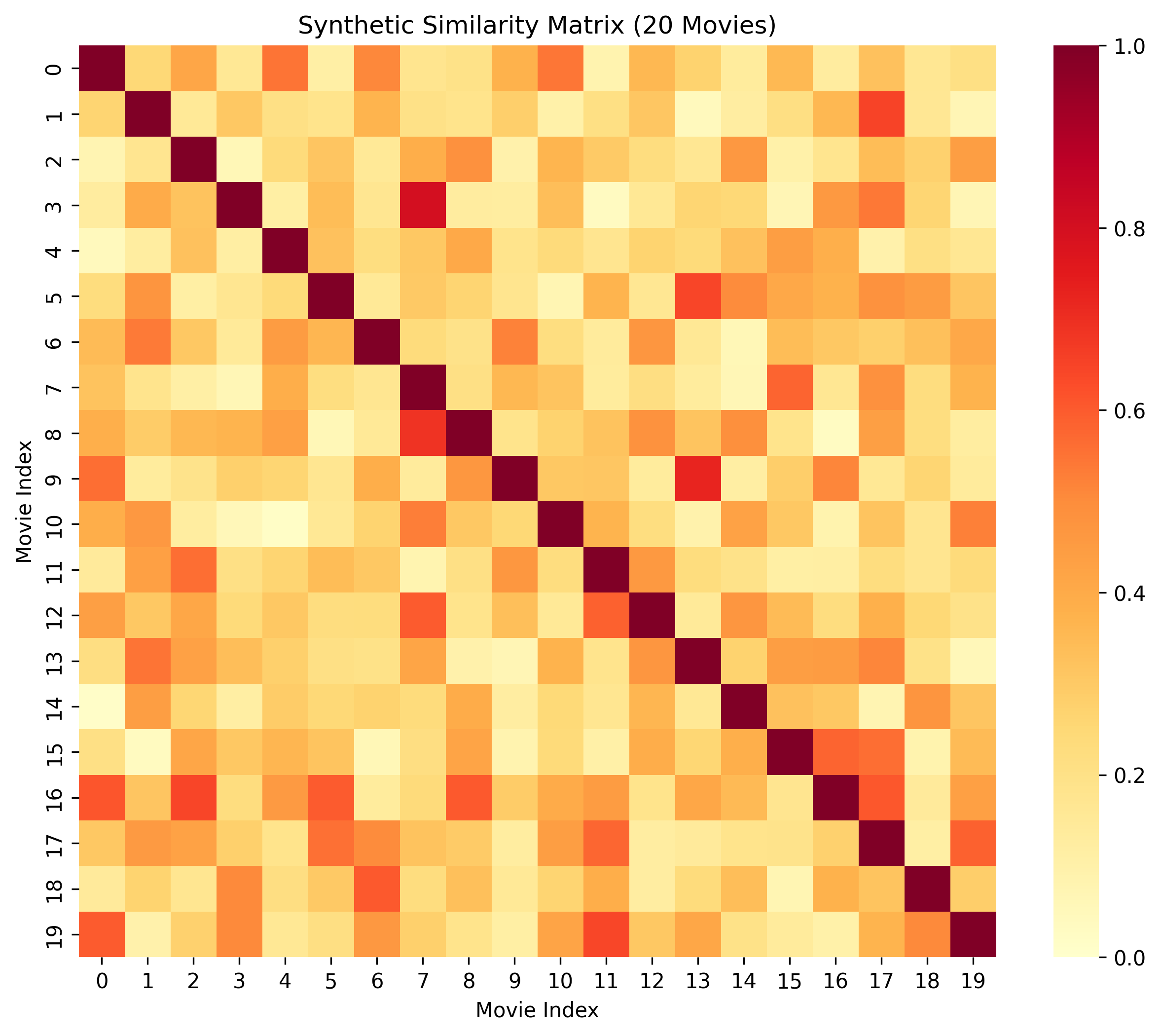
The cosine similarity matrix shows how movies are related to each other based on their combined features.
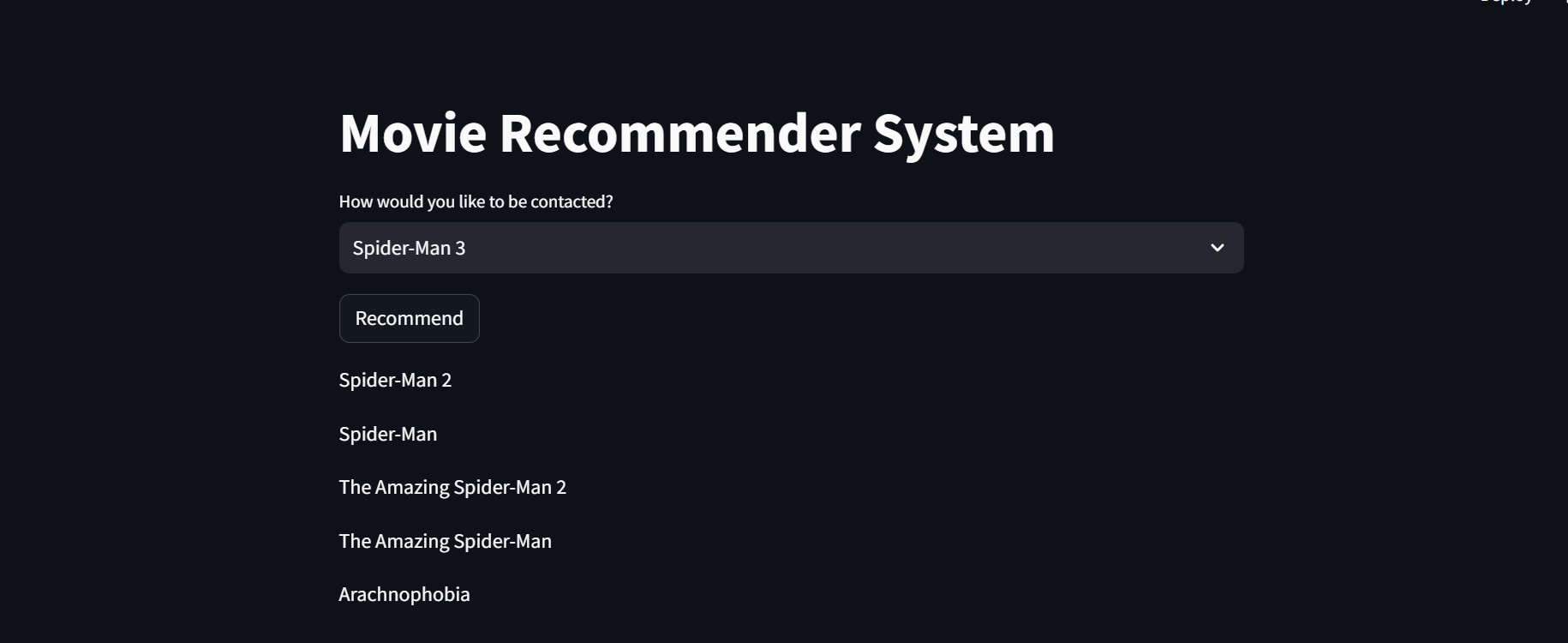
The recommendation output shows the top 5 similar movies for a given input movie.
This video demonstrates the working of the recommendation model:
- Real-time movie recommendation generation
- System response to different input movies
- Visualization of similarity scoring
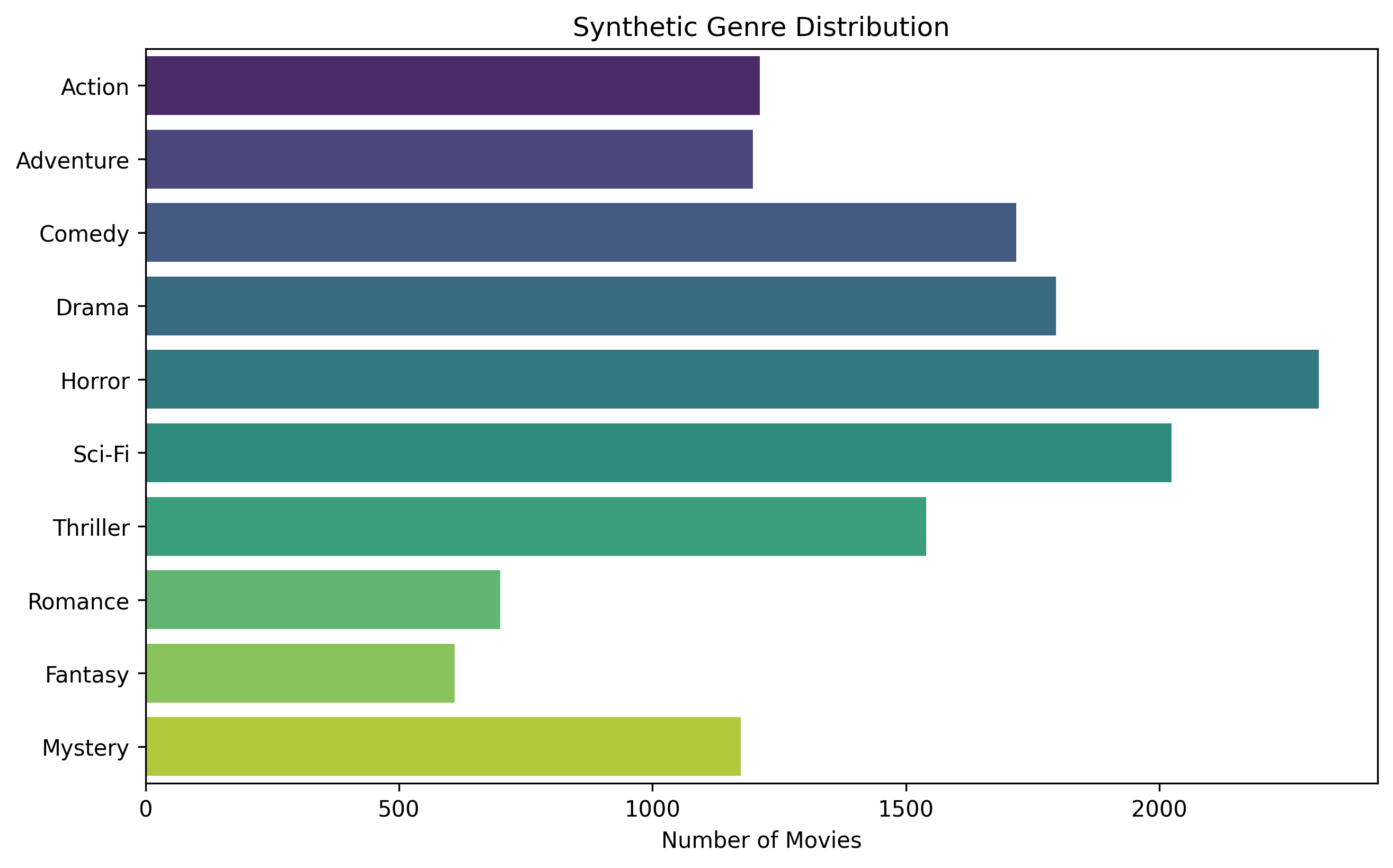
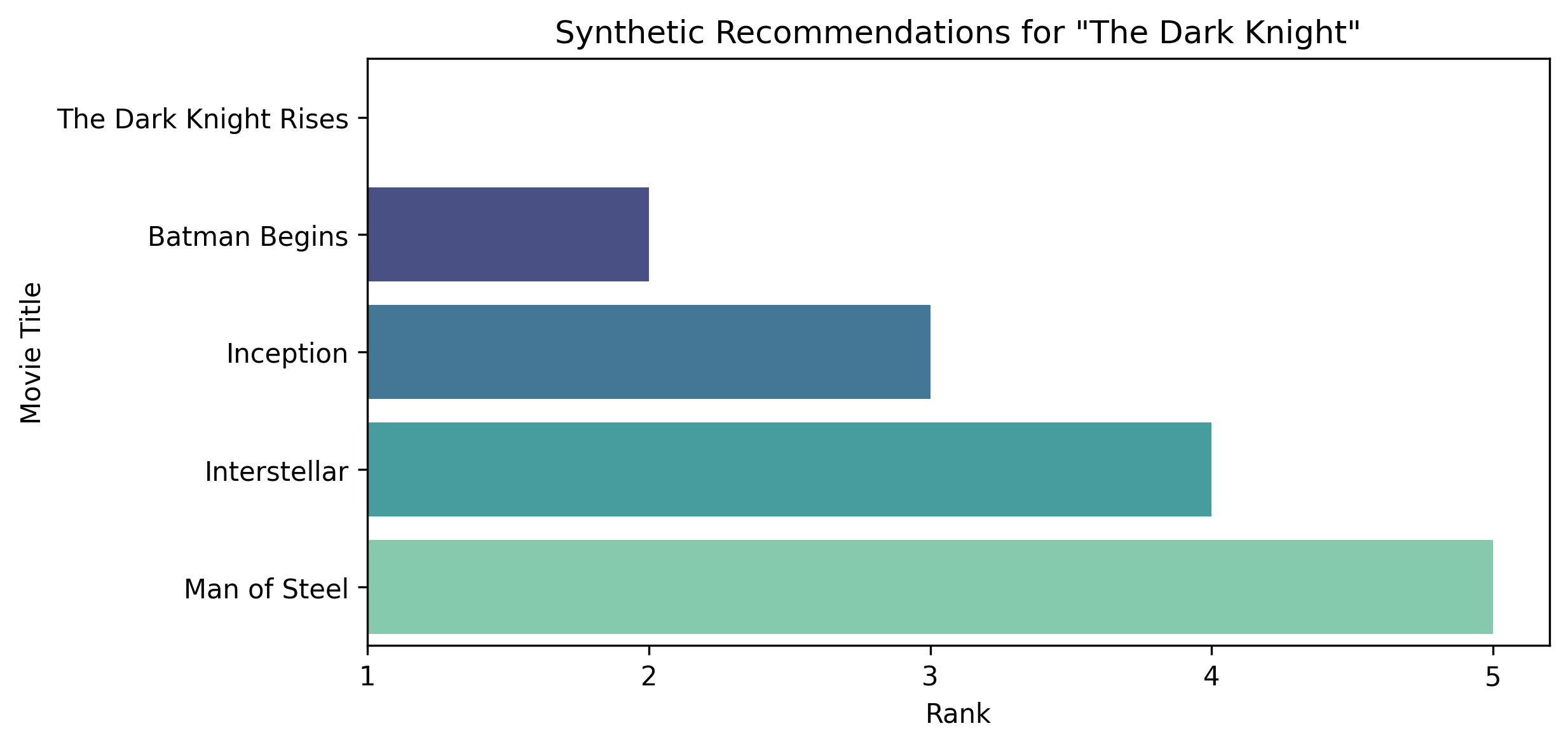
Technical Challenges & Solutions
The dataset contained JSON-like strings in columns like genres, keywords, cast, and crew that needed to be parsed.
Solution: Implemented custom parsing functions using ast.literal_eval to:
- Extract genre names from nested dictionaries
- Get top 3 cast members
- Identify directors from crew
- Combine all relevant features
Text features needed normalization to improve recommendation quality.
Solution: Implemented:
- Space removal between names (Tom Cruise → TomCruise)
- Lowercasing all text
- Porter stemming to reduce words to root forms
- Combination of all features into a single "tags" column
Calculating similarity between 5000+ movies with high-dimensional vectors.
Solution: Applied:
- CountVectorizer with max_features=5000 to limit dimensionality
- Cosine similarity for measuring similarity between vectors
- Efficient matrix operations with NumPy
- Pre-computed similarity matrix for fast recommendations
Key Code Implementation
Data Parsing and Cleaning
import ast
import pandas as pd
from nltk.stem import PorterStemmer
# Function to convert JSON-like strings to lists
def convert_to_list(objects):
new_list = []
for item in ast.literal_eval(objects):
new_list.append(item['name'])
return new_list
# Function to get top 3 cast members
def convert3(objects):
new_list = []
counter = 0
for item in ast.literal_eval(objects):
if counter != 3:
new_list.append(item['name'])
counter += 1
else:
break
return new_list
# Function to get director from crew
def convert_crew(objects):
new_list = []
for item in ast.literal_eval(objects):
if item['job'] == 'Director':
new_list.append(item['name'])
break
return new_list
# Apply parsing functions
movies['genres'] = movies['genres'].apply(convert_to_list)
movies['keywords'] = movies['keywords'].apply(convert_to_list)
movies['cast'] = movies['cast'].apply(convert3)
movies['crew'] = movies['crew'].apply(convert_crew)Text Processing and Feature Combination
# Process overview text
movies['overview'] = movies['overview'].apply(lambda x: x.split())
# Remove spaces between names and lowercase
movies['cast'] = movies['cast'].apply(lambda x: [i.replace(" ", "") for i in x])
movies['crew'] = movies['crew'].apply(lambda x: [i.replace(" ", "") for i in x])
movies['overview'] = movies['overview'].apply(lambda x: [i.replace(" ", "") for i in x])
movies['keywords'] = movies['keywords'].apply(lambda x: [i.replace(" ", "") for i in x])
# Combine all features into tags
movies['tags'] = movies['genres'] + movies['overview'] + movies['keywords'] + movies['cast'] + movies['crew']
# Convert list to string
movies['tags'] = movies['tags'].apply(lambda x: " ".join(x))
# Apply stemming
ps = PorterStemmer()
def stem(text):
lis = []
for i in text.split():
lis.append(ps.stem(i))
return " ".join(lis)
movies['tags'] = movies['tags'].apply(stem)Vectorization and Recommendation
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# Create count vectors
cv = CountVectorizer(max_features=5000, stop_words='english')
vectors = cv.fit_transform(movies['tags']).toarray()
# Calculate cosine similarity
similarity = cosine_similarity(vectors)
# Recommendation function
def recommend(movie):
movie_index = movies[movies['title'] == movie].index[0]
distances = similarity[movie_index]
movies_list = sorted(list(enumerate(distances)), reverse=True, key=lambda x: x[1])[1:6]
for i in movies_list:
print(movies.iloc[i[0]].title)
# Example usage
recommend('The Dark Knight')