MNIST Fake Image Generation with GANs
A Generative Adversarial Network (GAN) implementation that generates realistic handwritten digits by learning from the MNIST dataset.
Project Overview
This project implements a Generative Adversarial Network (GAN) to generate realistic handwritten digit images by learning from the MNIST dataset, demonstrating the power of deep learning in synthetic data generation.
The GAN consists of two competing neural networks - a generator that creates fake images and a discriminator that tries to distinguish real from fake. Through adversarial training, the generator learns to produce increasingly convincing digit images while the discriminator becomes better at detection.
GAN Architecture

Technical Highlights
Generator Network
- Input: 100-dim random noise vector
- Architecture: Dense → Reshape → Conv2DTranspose layers
- Output: 28×28 grayscale image
- Uses LeakyReLU activation
Discriminator Network
- Input: 28×28 grayscale image
- Architecture: Conv2D → LeakyReLU → Dropout
- Output: Binary classification (real/fake)
- Uses sigmoid activation
Training Process
- Batch size: 256
- Epochs: 50
- Optimizer: Adam (lr=1e-4)
- Loss: Binary cross-entropy
Technologies
- TensorFlow/Keras for model building
- NumPy for data manipulation
- Matplotlib for visualization
- Google Colab for GPU acceleration
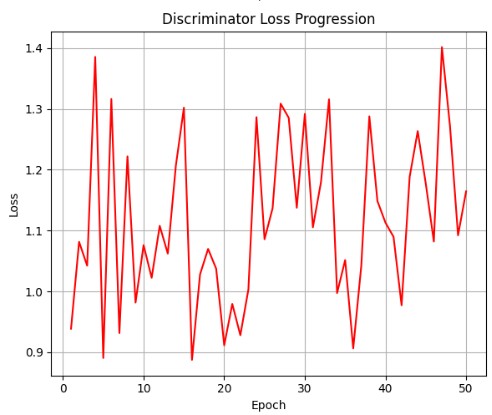
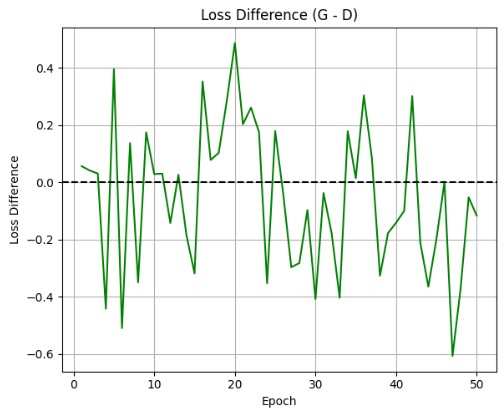
Training Results
Generator Loss
1.24
Final epochDiscriminator Loss
0.68
Final epochTraining Time
~2 hours
On Colab GPUTraining Dynamics
The adversarial training process showed:
- Initial Phase: Discriminator quickly learns to distinguish real/fake
- Middle Phase: Generator improves quality as discriminator gets stronger
- Final Phase: Equilibrium where both networks improve together
Generated Image Samples




Project Links
View Source Code View Visualizations Download Jupyter File📊 Project Details
- Status: Completed
- Dataset: 60,000 MNIST images
- Image Size: 28×28 grayscale
- Framework: TensorFlow 2.x
Technology Stack
Core Libraries
TensorFlow Keras NumPy MatplotlibModel Architecture
GANs Conv2D Conv2DTranspose LeakyReLUTraining
Adam Optimizer Binary Crossentropy GPU AccelerationDataset Information
MNIST Dataset
- 60,000 training images
- 10,000 test images
- 10 classes (digits 0-9)
- 28×28 pixel grayscale
- Normalized to [-1, 1] range
Preprocessing
Images reshaped to (28, 28, 1) and normalized
Training Visualizations
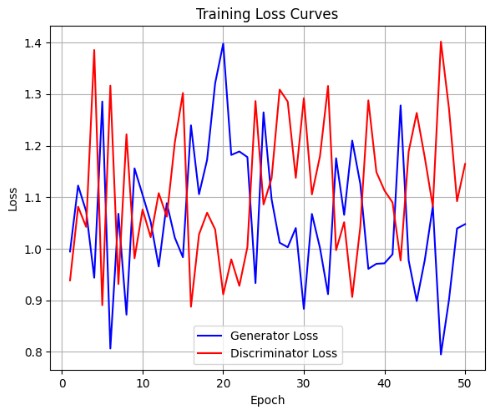
The loss curves show the adversarial training dynamics between generator and discriminator. The generator loss decreases as it learns to produce more convincing images, while the discriminator maintains reasonable accuracy in distinguishing real from fake.






Image quality progression over training epochs shows the generator's improvement from random noise (epoch 1) to recognizable digits (epoch 50). The model learns to capture the essential features of handwritten digits.
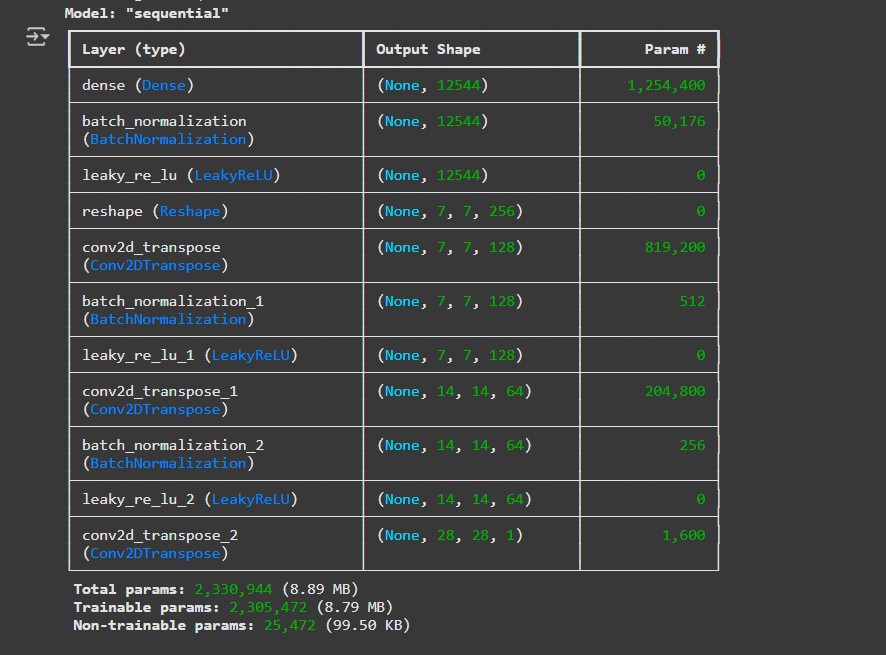
Generator Architecture
Discriminator Architecture
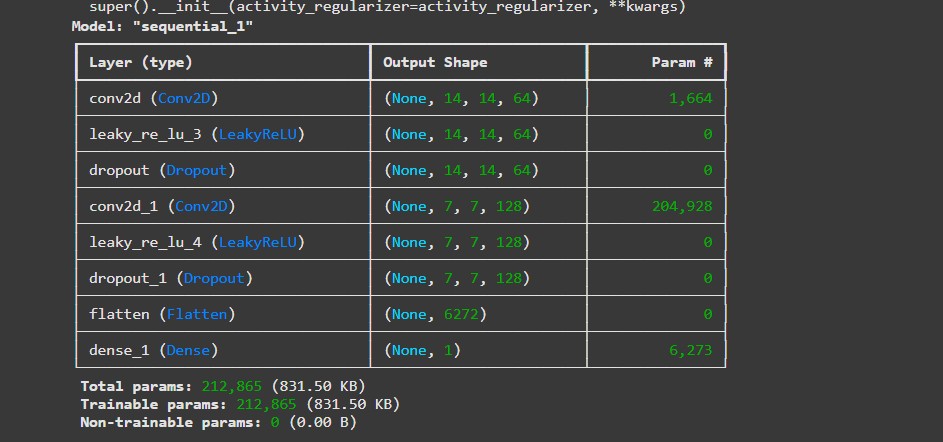
The generator uses transposed convolutions to upsample from random noise to 28×28 images, while the discriminator uses strided convolutions to classify images as real or fake. Both networks use batch normalization and LeakyReLU activations.
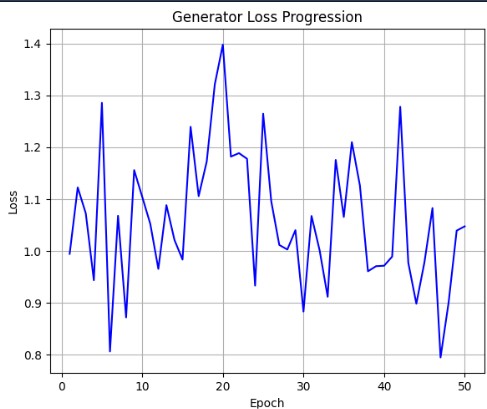
Technical Challenges & Solutions
The generator would sometimes produce limited varieties of digits (e.g., only generating 1s and 7s) instead of the full range of MNIST digits.
Solution: Implemented techniques like feature matching, minibatch discrimination, and careful tuning of learning rates to encourage diversity in generated samples.
GAN training is notoriously unstable, with common issues like vanishing gradients or one network overpowering the other.
Solution: Used techniques like label smoothing, gradient penalty, and balanced training schedule to maintain stable training dynamics.
Early generated images were blurry and lacked sharp features of real handwritten digits.
Solution: Improved architecture with deeper networks, batch normalization, and appropriate activation functions to enhance image quality.
Key Code Implementation
Generator Model Definition
def build_generator():
model = tf.keras.Sequential([
layers.Dense(7*7*256, use_bias=False, input_shape=(100,)),
layers.BatchNormalization(),
layers.LeakyReLU(alpha=0.2),
layers.Reshape((7, 7, 256)),
layers.Conv2DTranspose(128, (5,5), strides=(1,1),
padding='same', use_bias=False),
layers.BatchNormalization(),
layers.LeakyReLU(alpha=0.2),
layers.Conv2DTranspose(64, (5,5), strides=(2,2),
padding='same', use_bias=False),
layers.BatchNormalization(),
layers.LeakyReLU(alpha=0.2),
layers.Conv2DTranspose(1, (5,5), strides=(2,2),
padding='same', use_bias=False,
activation='tanh')
])
return modelDiscriminator Model Definition
def build_discriminator():
model = tf.keras.Sequential([
layers.Conv2D(64, (5,5), strides=(2,2),
padding='same', input_shape=[28,28,1]),
layers.LeakyReLU(alpha=0.2),
layers.Dropout(0.3),
layers.Conv2D(128, (5,5), strides=(2,2), padding='same'),
layers.LeakyReLU(alpha=0.2),
layers.Dropout(0.3),
layers.Flatten(),
layers.Dense(1, activation='sigmoid')
])
return modelTraining Loop
tf.function
def train_step(images):
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss,
generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss,
discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator,
generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator,
discriminator.trainable_variables))